AM-MobileNet1D: A Portable Model for Speaker Recognition
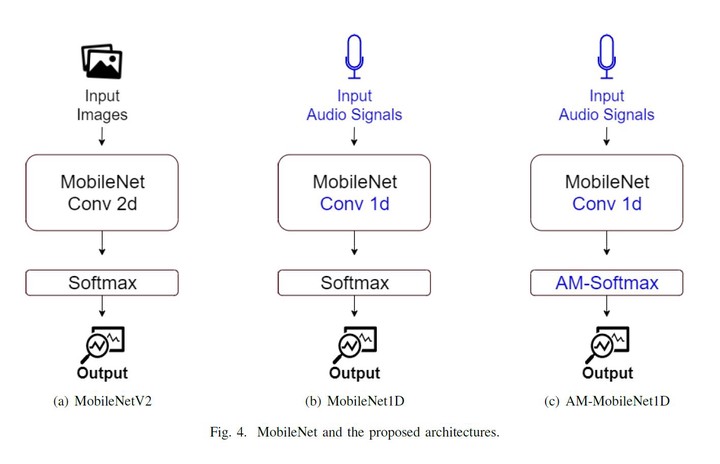 Photo by Authors
Photo by AuthorsSpeaker Recognition and Speaker Identification are challenging tasks with essential applications such as automation, authentication, and security. Deep learning approaches like SincNet and AM-SincNet presented great results on these tasks. The promising performance took these models to real-world applications that becoming fundamentally end-user driven and mostly mobile. The mobile computation requires applications with reduced storage size, non-processing and memory intensive and efficient energy-consuming. The deep learning approaches, in contrast, usually are energy expensive, demanding storage, processing power, and memory. To address this demand, we propose a portable model called Additive Margin MobileNet1D (AM-MobileNet1D) to Speaker Identification on mobile devices. We evaluated the proposed approach on TIMIT and MIT datasets obtaining equivalent or better performances concerning the baseline methods. Additionally, the proposed model takes only 11.6 megabytes on disk storage against 91.2 from SincNet and AM-SincNet architectures, making the model seven times faster, with eight times fewer parameters.