Additive Margin SincNet for Speaker Recognition
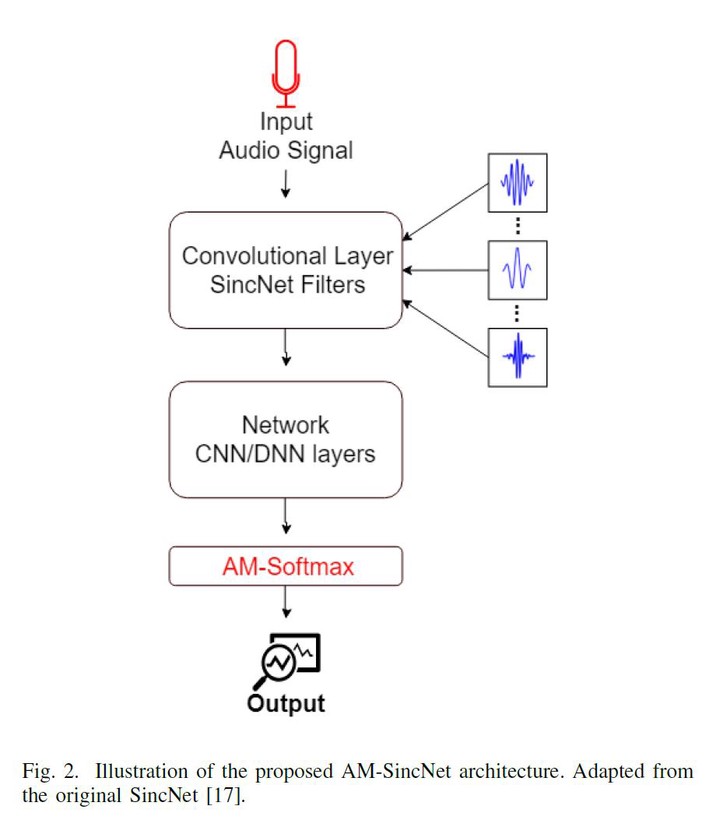 Photo by Authors
Photo by AuthorsSpeaker Recognition is a challenging task with essential applications such as authentication, automation, and security. The SincNet is a new deep learning based model which has produced promising results to tackle the mentioned task. To train deep learning systems, the loss function is essential to the network performance. The Softmax loss function is a widely used function in deep learning methods, but it is not the best choice for all kind of problems. For distance-based problems, one new Softmax based loss function called Additive Margin Softmax (AM-Softmax) is proving to be a better choice than the traditional Softmax. The AM-Softmax introduces a margin of separation between the classes that forces the samples from the same class to be closer to each other and also maximizes the distance between classes. In this paper, we propose a new approach for speaker recognition systems called AM-SincNet, which is based on the SincNet but uses an improved AM-Softmax layer. The proposed method is evaluated in the TIMIT dataset and obtained an improvement of approximately 40% in the Frame Error Rate when compared to SincNet.