SegNetRes-CRF: A Deep Convolutional Encoder-Decoder Architecture for Semantic Image Segmentation
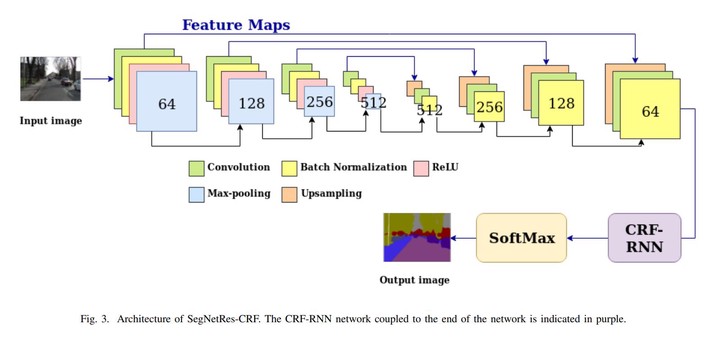 Photo by Authors
Photo by AuthorsSemantic segmentation is an essential task in computer vision that aims to label each image pixel. Several of the actual best approaches in this context are based on deep neural networks. For example, SegNet is a deep encoder-decoder architecture approach whose results were disruptive because it is fast and performs well. However, this architecture fails to fine-delineating the edges between the objects of interest in the image. We propose some modifications in the SegNet-Basic architecture by using a post-processing segmentation layer (using Conditional Random Fields) and by transferring high resolution features combined to the decoder network. The proposed method was evaluated in the dataset CamVid. Moreover, it was compared with important variants of SegNet and showed to be able to improve the overall accuracy of SegNet-Basic by up to 17.5%.